This summer, I continued working at Wander on a React Native mobile application for our iOS users. I built a product to scratch an itch with FitBit’s food logging capabilities. And I started my first software engineering (SWE) internship at Comcast (Effectv), working on TV Ad-tech solutions.
Wander
Wander is a social media startup founded by University of Michigan alum Justin Gainsley and Yash Ramachandani. Wander was created on the premise that we form more meaningful connections with those that share the same interests/hobbies as us rather than the places we’ve been or the food that we’ve eaten.
How is Wander different from X?
Last summer, I ran into a high school friend of mine who was rising junior studying Computer Science at Berkeley. We caught up and I told him I was working at social media startup called Wander. I explained the whole shtick: “Wander is a platform to allow people to discuss intellectual content with their network”. Usually people just nod their heads and say “Oh, that’s cool!”, but he asked me a question I hadn’t really thought about before: “How is Wander different from X?”. After working at Wander for more than a year, here is my answer.
From my experience, social media apps are distinguished by how it allows its users to generate content. For example, TikTok is the king of short-form video, where most content averages around ~21-30 seconds. Snapchat capitalizes on the spontaneous nature of the world and lets you upload raw footage of stuff going on around you. Instagram is a modern, digital version of an old photo album: you take all your pictures, and put them into mini albums or posts. Although Twitter does allow posting photo and video content, its primary focus is on quick, directed, and concise user generated text. On the other hand, Wander emphasizes curation as a method of “generating” content. Here is my Wander feed.
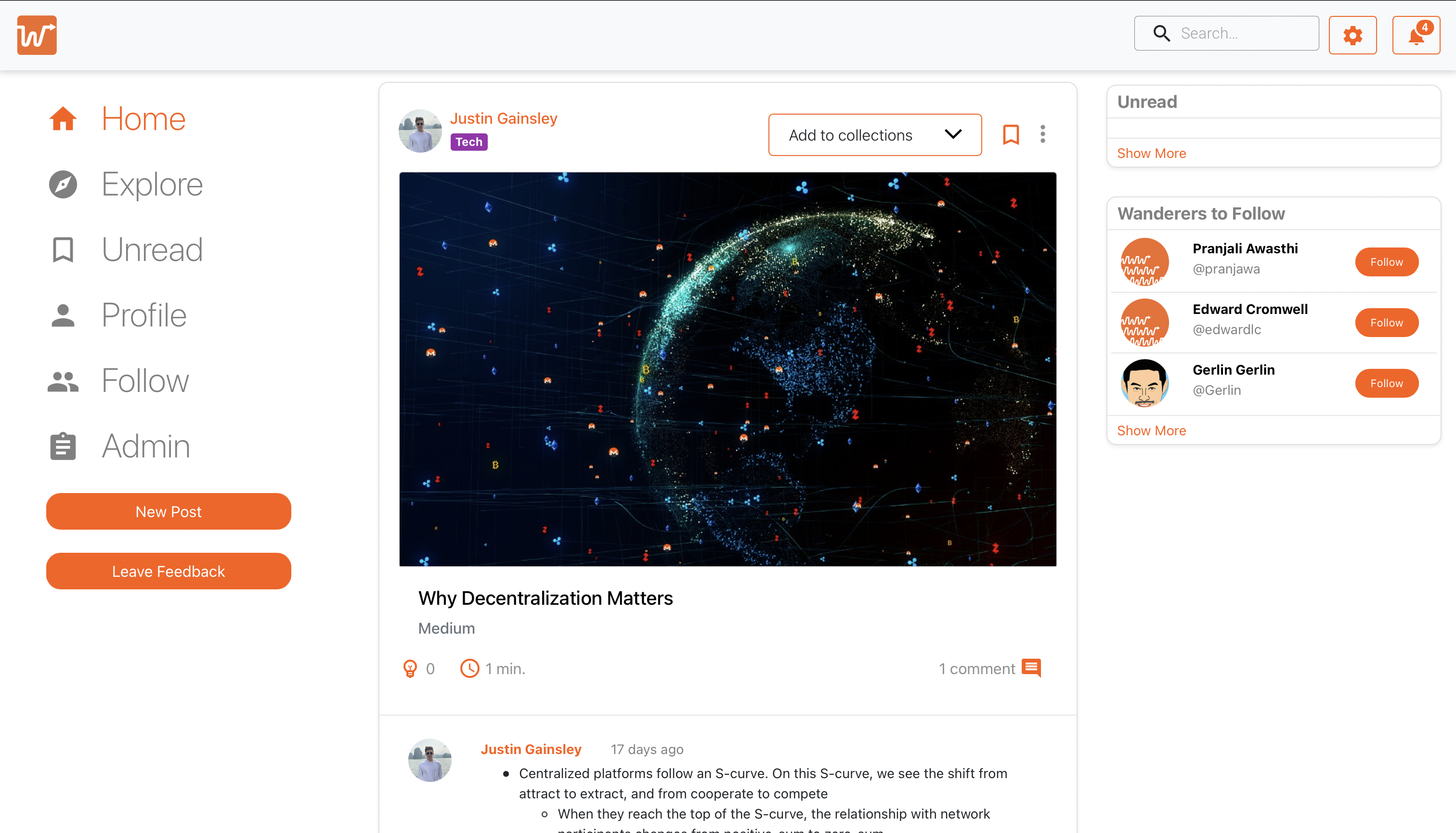
From the UI, it is clear that Justin posted this, but the article is not written by him. It’s just a Medium article that he found, which compelled him to post it on Wander in the hopes of creating discourse. Every user is the content curator of their own interests which makes Wander the best place discuss and develop your interests on the internet. In my opinion, this is Wander’s niche.
Web -> Mobile
In my experience, when you’re starting to build an app, there’s two routes that are
open to you as the developer: mobile-first or web-first. For most use cases, I
think a web-first approach is the way to go. You don’t have to wait months to
launch (👀 App Store) which makes iterative development stupid simple, you can
still make your web app mobile-friendly with simple media-queries, and you can
pick and choose from a large variety of web technologies. If your app grows and
you have the bandwidth to support both the mobile and web platform, you can always
make that addition.
By early 2022, our web app had matured and we made the transition to developing our React Native mobile app exclusive to iOS (for now). Knowing React significantly improved my productivity, and it only took me a couple of sessions of focused development to start implementing features for the app. Even with the backend infrastructure already available, it was not an easy lift and shift job. School and other distractions made it difficult to iterate quickly, so I opted to start when I had more bandwidth. Few weeks into my summer break, I implemented features such as in-app browsing, adding to unread/ collections/playlists, displaying notifications, and a functioning infinite scroll mechanism. Below is a brief demo of that work. (Note: Most of the work you see in the video is by me!)
Overall, my first project with React Native was pretty fun. Being able to build mobile applications with web technologies is super powerful and intuitive.
FitBit Recipe Importer
From a bird’s eye view, the Fitbit app is well-designed, and all the information you need is readily available at a glance. But, in my opinion, its macro/food tracking experience is subpar. I love trying online recipes in my free time, but I get super frustrated when it’s time to track it because I have to keep swapping between the recipe and the app and input each nutrient one by one. At first glance, it seemed like a super cool engineering problem and decided that I would tackle it for fun.
Approach #1
My initial approach was to build a web scraper to find where the nutritional information was in the HTML markup, extract it, and return the data in JSON format. This was a miserable experience. One of the biggest problems with this approach is no recipe blog is built the same. There is no consistency across pages, so one parsing method might work for a couple of sites, but wasn’t a generic solution. So, I quickly abandoned this approach.
Approach #2
In my research, I found a
blog post
by Jed Simon who worked on exactly the same problem. He found out that recipe
blogs use a special type of metadata contained in a script tag with an application\ld+json
type to provide Google’s web crawlers all sorts of information about their recipe. This information
includes images of each step in the cooking process, step-by-step instructions, ingredients,
prep/cook times, and so much more (full list here).
I decided that this was definitely the best possible approach and started
building a prototype with this approach in mind.
Sample application\ld+json
{
"@context": "https://schema.org/",
"@type": "Recipe",
"name": "Party Coffee Cake",
"image": [
...
],
"author": {
"@type": "Person",
"name": "Mary Stone"
},
"datePublished": "2018-03-10",
"description": "This coffee cake is awesome and perfect for parties.",
"prepTime": "PT20M",
"cookTime": "PT30M",
"totalTime": "PT50M",
"keywords": "cake for a party, coffee",
"recipeYield": "10",
"recipeCategory": "Dessert",
"recipeCuisine": "American",
"nutrition": {
"@type": "NutritionInformation",
"calories": "270 calories"
},
"recipeIngredient": [
"2 cups of flour",
"3/4 cup white sugar",
"2 teaspoons baking powder",
"1/2 teaspoon salt",
"1/2 cup butter",
"2 eggs",
"3/4 cup milk"
],
"recipeInstructions": [
...
]
}* Credit: Google Search documentation
MVP
A well-designed programming project is 80% planning and 20% coding. This was the case here as well. The entire timeline was two weeks. I spent about a week and a half planning, researching valid approaches, prototyping quick solutions, and choosing which technolgies to use. The actual engineering was simple.
On a side note, I decided to use this project to learn more about containers and Docker.
For this project, I spun up a container running my FastAPI
REST API with a single endpoint with the path /parse. The /parse endpoint did the following things upon
recieving a request:
- validate the link using regex
- request the HTML markup of the link
- find the
application\ld+jsonscript - validate the json
- extract nutrition information and ingredients
- construct response json
There were some hiccups with step 2, but I worked around that by using user-agent spoofing and it worked like a charm! I used the BeautifulSoup library to deal with the finding tags in the markup and then used basic Python to get the rest of the steps working.
The frontend was built using Vite + React and styled with TailwindCSS. Within a couple
of days, I wrapped up frontend development and had it working end-to-end. Below
is a demo of the app or you can check it out for yourself
here!
The backend is deployed on Heroku and the frontend is deployed on Netlify. Both services made it extremely easy to deploy my code and plus they had free tiers!
Launch 🎉
This project was motivated to scratch my own itch, but was curious if this was something other FitBit users were frustrated with as well. I’ve tried launching projects through Reddit, but a huge problem with moderated subreddits are the strict “no self-promotion” rules. Luckily, r/fitbit didn’t have any restrictions. I carefully wrote a post talking about the motivation for the project and linked a quick demo (same as above) and a link for people to try it out. (Here is the post)
The response was unimaginable. People were loving it! For the number nerds, here are some metrics after launching.
Metrics
- Within 48 hours, the post recieved close to 60 upvotes and 10.6k views
- Within the first month, the site had nearly 200+ unique visitors
- Within three months, the site is closing in on 300 unique visitors
* Data provided by Netlify Analytics
The code is far from perfect, and sometimes when I peek at the Heroku logs,
I find Internal Server Errors every once in a while. I’ve been thinking of
enhancements over the past 3 months, but haven’t had the time to start work on them
because of my internship. But hopefully I’ll be able to start planning and working
on a v2 soon!
Comcast
This summer I worked as an engineering intern at Effectv which is one of two advertising companies within Comcast. My team worked in the ad delivery space ensuring that the correct ads end up at the correct channels on time. During my 11 weeks, I had two roles: Scrum Master and Software Engineer. As the scrum master, I was responsible for conducting various Agile ceremonies such as Daily Standup and Sprint Retrospective. As a software engineer, I worked with other engineers maintaining and enhancing our core product called Enterprise Schedule & Verification Platform (or ESVP).
Steel Cloud Migration
My first task involved redeploying two critical applications onto a new server. One app was called “Server Restart Tool” which enabled engineers to remotely restart any server. It was built with Django and deployed on a legacy web server tool called Internet Information Services (IIS). The other was an Angular (🤢) application deployed using the same tool. This mini-project was super tedious because work just involved copying over the files from one Windows server to the other, and then spending hours configuring IIS. At the time, it didn’t seem like useful information, but exposure to IIS this early helped me when I was working on PAA Monitor Tool towards the end of my internship.
Test Driven Development
After the app migration project, I spent about a week exploring Test Driven Development (TDD) in Go by writing tests for common functions used by the ESVP codebase. The beauty of Go is that testing is built directly into the language, there is absolutely NO configuration. All batteries are included. Plus they have awesome test tooling to automatically calcuate code coverage and even visualize which parts of your code are being covered!!
* Credit: Yuri Fedorov
ESVP is a huge codebase (~580,000 LOC) and a cool side effect of writing tests early on in my internship was that it helped me understand the big picture. It significantly helped me ramp up when I started adding enhancements to the codebase. I knew how all the pieces fit together and working on tests gave me the oppurtunity to dive deeper in to the code base. Although I hate writing tests, it ended up paying dividends in my speed of code output.
My contributions to ESVP
AWS SAM CLI
ESVP has been running on premises (on servers directly owned and managed by Comcast) since its inception. Jetway is an effort to refactor ESVP to use AWS cloud infrastructure and eventually sunset on premises servers. One of the first things I worked on was setting up a suite of tools to test lambdas locally. Our team had used LocalStack in the past but many noted that it was hard to configure for testing only a handful of endpoints. I discovered the AWS SAM CLI from the AWS Documentation, experimented with it on my end, and wrote up a technical guide for setting up the AWS SAM CLI to work with Go and get our Lambda functions running locally. This allowed our team to thoroughly test our backend before ever pushing to production and made me way more productive while working on Jetway.
CSV Exports/Imports
ESVP is used by over 300+ business users from Ad Operations teams and Sales
teams at Comcast which means that it handles an insane amount of data and traffic.
A typical workflow in ESVP will use CSV exports and imports with a huge number
rows and columns. In order to handle this at scale, I helped build an integration
with AWS S3 to automatically detect large file sizes and use a presigned S3 url
instead of a typical multipart form request. I also transformed the UX of exporting
data from the platform. Before my changes, file downloads were slow, CSV header
orderings didn’t match existing ESVP guidelines, and no data would result in
the completely empty CSV file. To fix the file downloads, I standardized
our JSON response schema for CSV files, and rewrote our JSON -> CSV deserialization
to be 15% faster. Comcast’s frontend was written completely in vanilla JS
and HTML so our JS was chockful of document.getElementByID which was
definitely fun to read and maintain 🥲. But, it did give me a far greater
appreciation for modern Javascript UI frameworks that abstract all of this
away.
reload
Developing apps in the Javascript ecosystem is blazingly fast, you keep the server running in the background and as soon as a file changes, you hit refresh, and your changes are there automagically. Since our Go apps are compiled, you can’t achieve live reload functionality out of the box. Here’s an illustration of how development work was done on our Go apps.
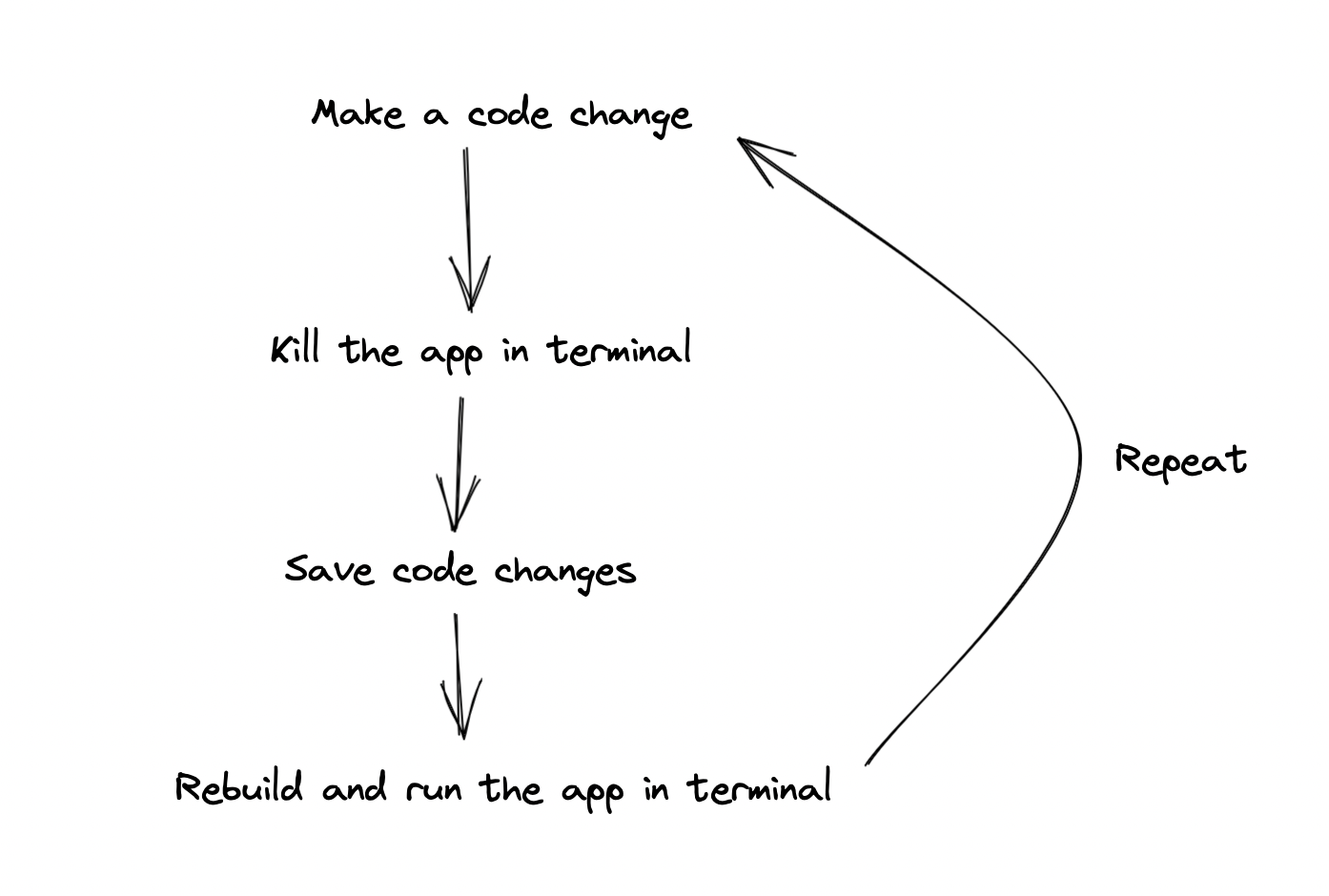
There are existing solutions, but didn’t have the tight integration with containers I was looking for. Also, it was an oppurtunity to help the team be more productive while learning more about Go. Here are the overarching goals of this project.
- Has to work with both containerized and non-containerized applications
- Has to be easily configurable
- Has to be easy to use
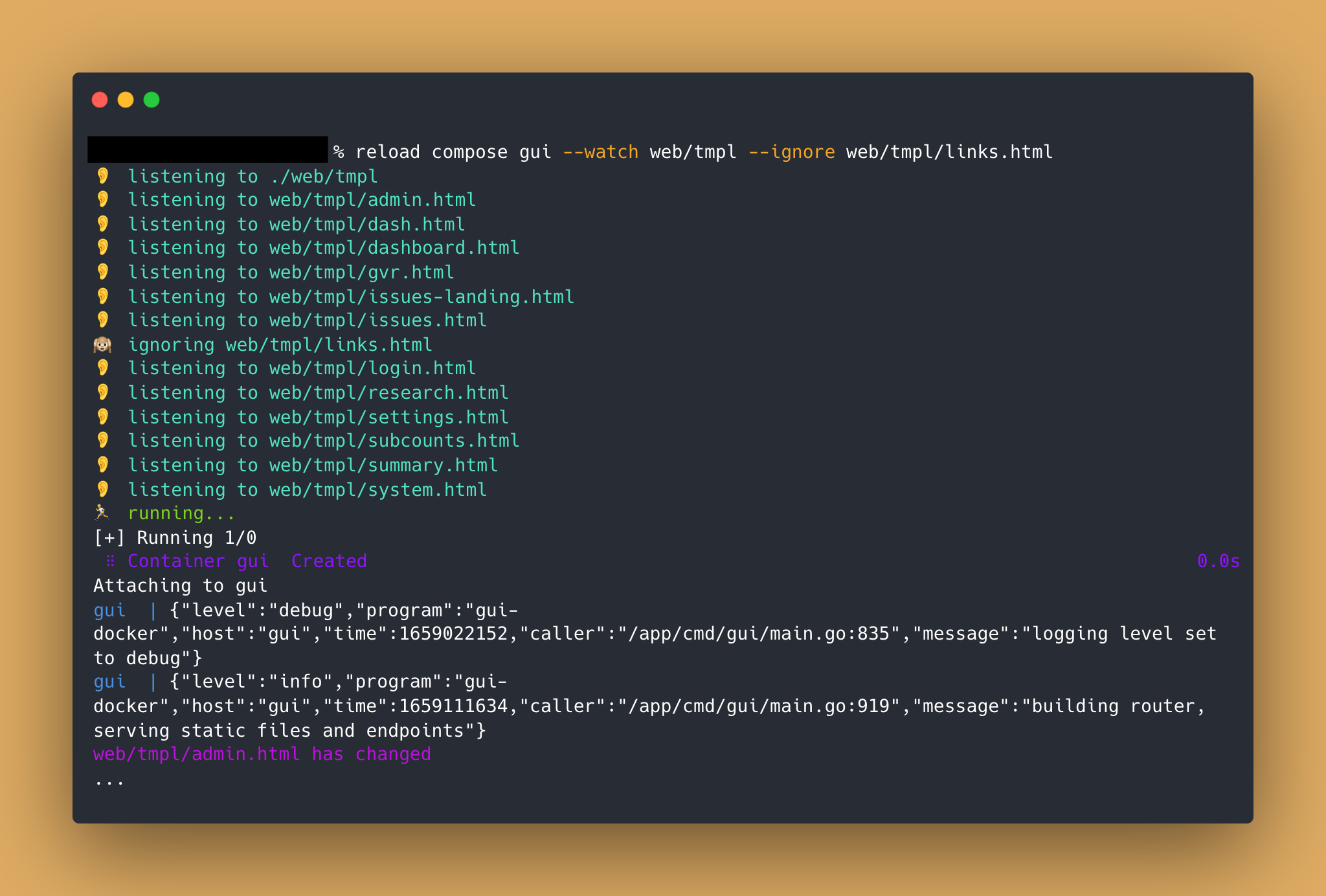
In about two weeks of work, I created reload. Reload is a CLI tool written
in Golang to inject live reload functionality for both containerized and
non-containerized applications in hopes of streamlining developer productivity
and promoting rapid iterative development on all applications. I’m planning on
creating a little demo of the tool soon. (Stay posted 👀) But for now, enjoy
this sweet screenshot.
Pull Request Notifier
Half way through my internship, our team size decreased and we lost our only QA engineer. We had to adapt and the engineering team assumed the role of QA’ing each others features which dramatically reduced development capacity. A side effect of this adaptation was an increase in open, unreviewed pull requests. At several points in time, we had like 15+ pull requests open without review. So I took initiative and built Pull Request Notifier. It’s a simple Slack app that queries GitHub for open pull requests in our org and sends a helpful message to our Slack channel telling our engineers to close out pull requests. Within a couple of days of use we were able to reduce our open pull requests from 15+ to 5. Below is a message sent after deployed into production.
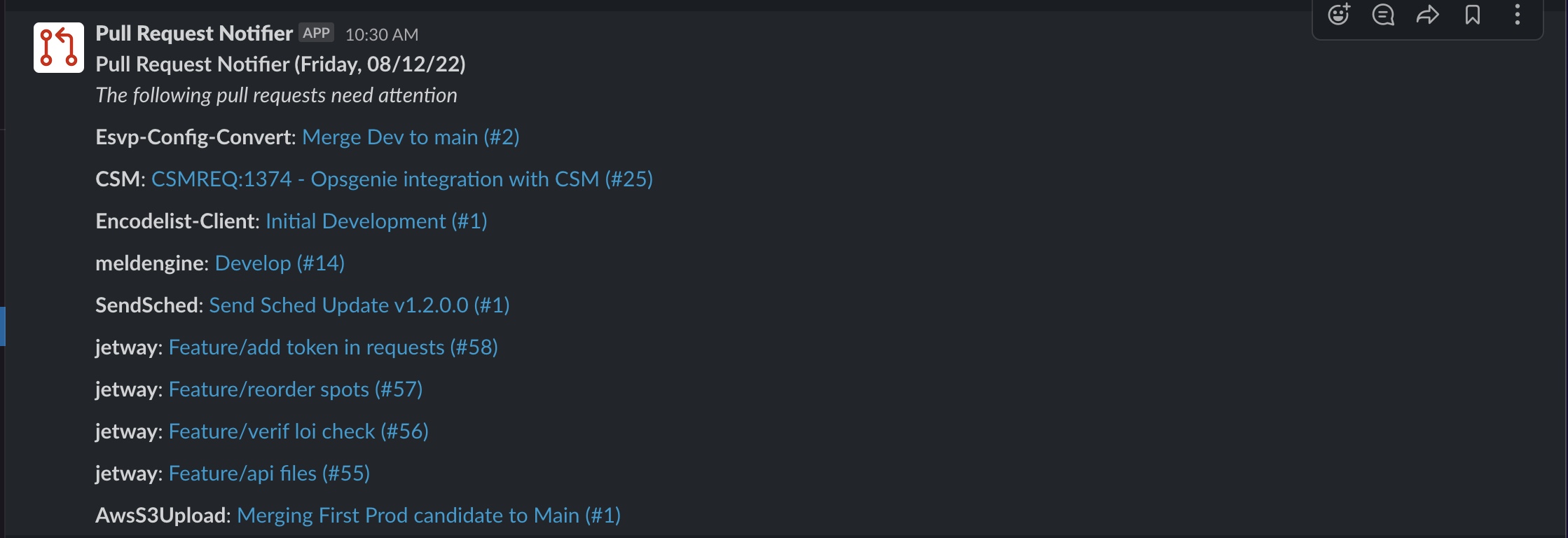
PAA Monitor Tool
Apart from ESVP, we own two other products called PAA and CSM. CSM is a legacy
Ad Delivery tool built in .NET and C# and PAA is an archive that handles
advertising during political campaigns (local, state, and national). Every day,
PAA handles importing data from the Operational Reporting team at Comcast.
Sometimes we haven’t recieved any data from the OpRep team which could mean
two things: the team has not posted any new information, or the PAA job that is
meant to process this new data is not in a healthy state. But there is no way
of knowing this has even occurred without thorough investigation into the
database containing these records. So, the PAA Monitor tool was built as a
small dashboard for the Comcast business to keep track of the last known
OpRep data recieved and whether or not PAA had processed it. Here is a view
of that dashboard.
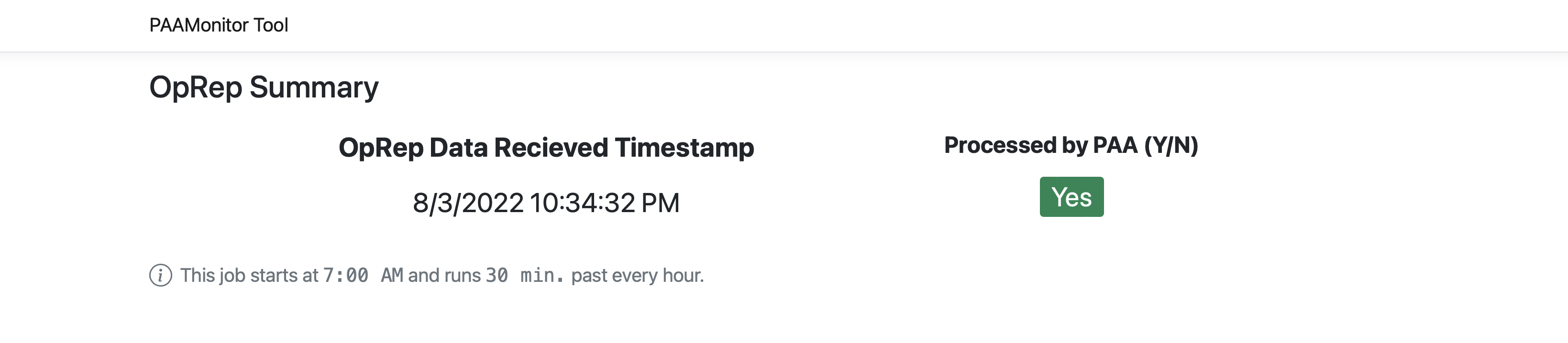
The dashboard was built with ASP .NET Core v6 using Razor Pages. This was my first exposure to building web applications using C# and it was refreshingly different from what I’m used to. It’s secured with Windows authentication which was a breeze to set up using IIS. It wasn’t all smooth sailing, but learned new things about IIS and an entire new web framework.
Additionally, I built a background job using Go that would notify our team with an email notification in the event of no OpRep data or PAA had not processed the data by 9:00 AM.
Conclusion
It wasn’t until I sat down to write this blog post that I realized all the things that I accomplished this summer. I don’t know if I’m ready to start school again, but I’m excited to see what the school year has in store for me.